4.27日学习打卡
目录:
- 4.27日学习打卡
- 一. Redis的配置文件
- 二. Redis构建Web应用实践
- 环境搭建
- redis的优点
- 引入本地缓存
- Google 开源工具Guava
- Guava实现本地缓存

一. Redis的配置文件
在Redis的解压目录下有个很重要的配置文件 redis.conf ,关于Redis的很多功能的配置都在此文件中完成的,一般为了不破坏安装的文件,出厂默认配置最好不要去改。
units单位
配置大小单位,开头定义基本度量单位,只支持bytes,大小写不敏感。
INCLUDES
Redis只有一个配置文件,如果多个人进行开发维护,那么就需要多个这样的配置文件,这时候多个配置文件就可以在此通过 include /path/to/local.conf 配置进来,而原本的 redis.conf 配置文件就作为一个总闸。
NETWORK
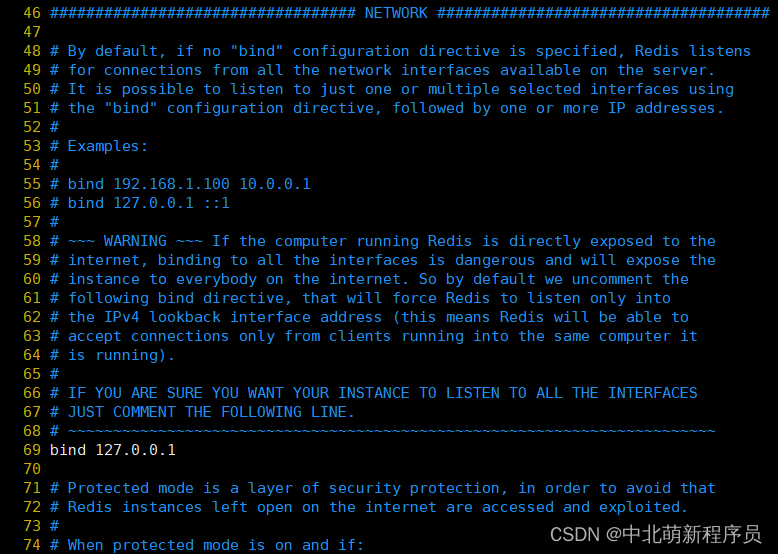
参数:
- bind:绑定redis服务器网卡IP,默认为127.0.0.1,即本地回环地址。这样的话,访问redis服务只能通过本机的客户端连接,而无法通过远程连接。如果bind选项为空的话,那会接受所有来自于可用网络接口的连接。
- port:指定redis运行的端口,默认是6379。由于Redis是单线程模型,因此单机开多个Redis进程的时候会修改端口。
- timeout:设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接。默认值为0,表示不关闭。
- tcp-keepalive :单位是秒,表示将周期性的使用SO_KEEPALIVE检测客户端是否还处于健康状态,避免服务器一直阻塞,官方给出的建议值是300s,如果设置为0,则不会周期性的检测。
GENERAL
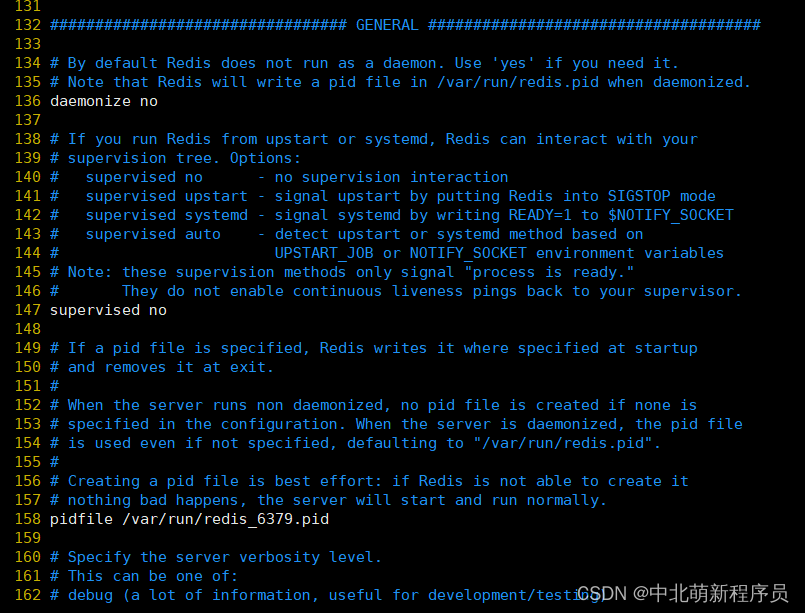
具体配置详解:
- daemonize:设置为yes表示指定Redis以守护进程的方式启动(后台启动)。默认值为 no
- pidfile:配置PID文件路径,当redis作为守护进程运行的时候,它会把 pid 默认写到 /var/redis/run/redis_6379.pid 文件里面
- loglevel :定义日志级别。默认值为notice,有如下4种取值:
- debug(记录大量日志信息,适用于开发、测试阶段)
- verbose(较多日志信息)
- notice(适量日志信息,使用于生产环境)
- warning(仅有部分重要、关键信息才会被记录)
- logfile :配置log文件地址,默认打印在命令行终端的窗口上
- databases:设置数据库的数目。默认的数据库是DB 0 ,可以在每个连接上使用select 命令选择一个不同的数据库,dbid是一个介于0到databases - 1 之间的数值。默认值是 16,也就是说默认Redis有16个数据库。
SNAPSHOTTING
这里的配置主要用来做持久化操作。
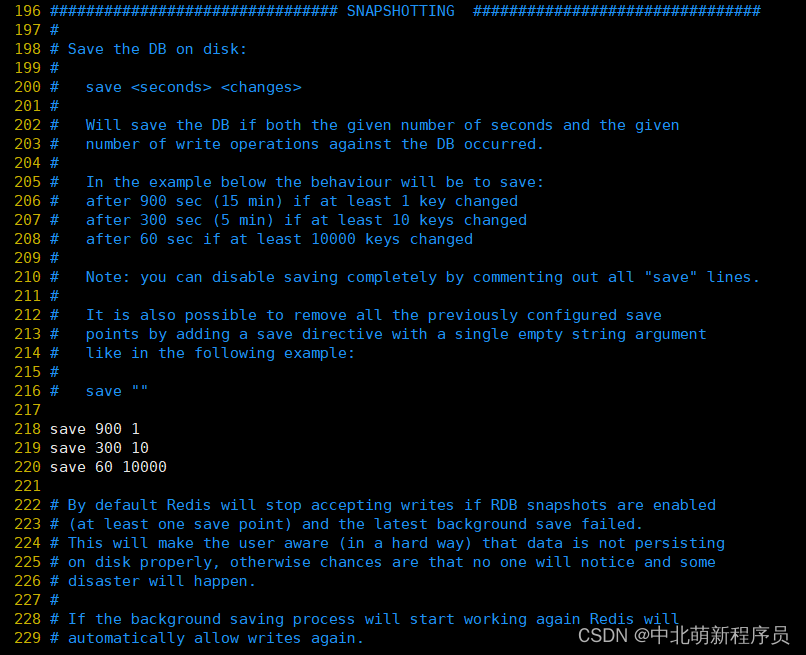
参数:
save:这里是用来配置触发 Redis的持久化条件,也就是什么时候将内存中的数据保存到硬盘
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
REPLICATION
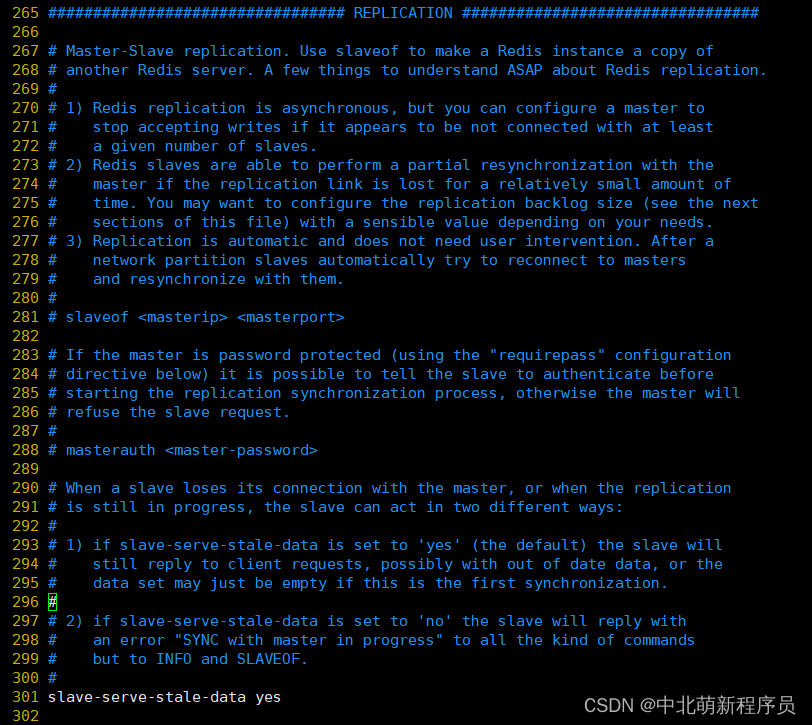
参数:
- slave-serve-stale-data:默认值为yes。当一个 slave 与 master 失去联系,或者复制正在进行的时候,
slave 可能会有两种表现:
- 如果为 yes ,slave 仍然会应答客户端请求,但返回的数据可能是过时,或者数据可能是空的在第一次同步的时候
- 如果为 no ,在你执行除了 info he salveof 之外的其他命令时,slave 都将返回一个 “SYNC with master in progress” 的错误
- slave-read-only:配置Redis的Slave实例是否接受写操作,即Slave是否为只读Redis。默认值为yes。
- repl-diskless-sync:主从数据复制是否使用无硬盘复制功能。默认值为no。
- repl-diskless-sync-delay:当启用无硬盘备份,服务器等待一段时间后才会通过套接字向从站传送RDB文件,这个等待时间是可配置的。
- repl-disable-tcp-nodelay:同步之后是否禁用从站上的TCP_NODELAY 如果你选择yes,
- redis会使用较少量的TCP包和带宽向从站发送数据。
SECURITY
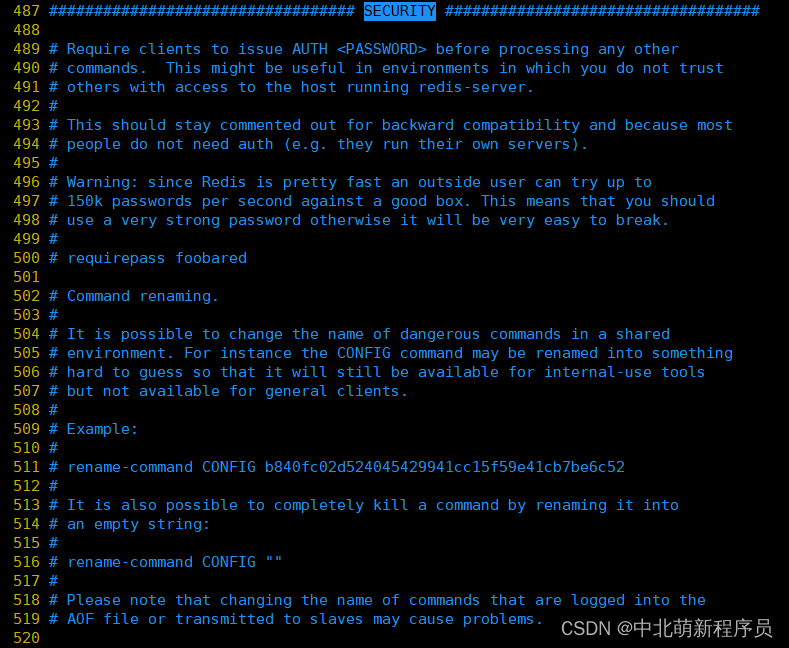
requirepass:设置redis连接密码。
比如: requirepass 123 表示redis的连接密码为123。

CLIENTS
参数:
maxclients :设置客户端最大并发连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件。 描述符数-32(redis server自身会使用一些),如果设置 maxclients为0 。表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
MEMORY MANAGEMENT
参数:
- maxmemory:设置Redis的最大内存,如果设置为0 。表示不作限制。通常是配合下面介绍的maxmemory-policy参数一起使用。
- maxmemory-policy :当内存使用达到maxmemory设置的最大值时,redis使用的内存清除策略。有以下几种可以选择:
1)volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
2)allkeys-lru 利用LRU算法移除任何key
3)volatile-random 移除设置过过期时间的随机key
4)allkeys-random 移除随机ke
5)volatile-ttl 移除即将过期的key(minor TTL)
6)noeviction noeviction 不移除任何key,只是返回一个写错误 ,默认选项- maxmemory-samples :LRU 和 minimal TTL 算法都不是精准的算法,但是相对精确的算法(为了节省内存)。随意你可以选择样本大小进行检,redis默认选择3个样本进行检测,你可以通过maxmemory-samples进行设置样本数。
APPEND ONLY MODE
参数:
- appendonly:默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式, 可以提供更好的持久化特性。Redis会把每次写入的数据在接收后都写入appendonly.aof文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。默认值为no。
- appendfilename :aof文件名,默认是"appendonly.aof"
- appendfsync:aof持久化策略的配置;no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快;always表示每次写入都执行fsync,以保证数据同步到磁盘;everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
LUA SCRIPTING
参数:
lua-time-limit:一个lua脚本执行的最大时间,单位为ms。默
认值为5000.
REDIS CLUSTER
参数:
- cluster-enabled:集群开关,默认是不开启集群模式。
- cluster-config-file:集群配置文件的名称。
- cluster-node-timeout :可以配置值为15000。节点互连超时的阀值,集群节点超时毫秒数
- cluster-slave-validity-factor :可以配置值为10。
二. Redis构建Web应用实践
环境搭建
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.5</version>
<exclusions>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>3.0.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
编写配置文件
spring.application.name=spring-redis
server.port=8080
########################################################
### 配置连接池数据库访问配置
########################################################
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/redistest?characterEncoding=utf-8&&useSSL=false
spring.datasource.username=root
spring.datasource.password=jjy18535155985
spring.data.redis.host=192.168.66.100
spring.data.redis.port=6379
创建表
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user`
(
id BIGINT NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (id)
);
DELETE FROM `user`;
INSERT INTO `user` (id, name, age, email) VALUES
(1, 'Jone', 18, 'test1@baomidou.com'),
(2, 'Jack', 20, 'test2@baomidou.com'),
(3, 'Tom', 28, 'test3@baomidou.com'),
(4, 'Sandy', 21, 'test4@baomidou.com'),
(5, 'Billie', 24, 'test5@baomidou.com');
编写实体类 User.java
@Data
@TableName("`user`")
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
编写 Mapper 包下的 UserMapper接口
public interface UserMapper extends BaseMapper<User> {
}
编写业务层
@Service
public class UserService {
@Autowired
UserMapper userMapper;
public User getUser(Long id){
return userMapper.selectById(id);
}
}
编写控制层
@RestController
public class UserController {
@Autowired
UserService userService;
/**
* 根据id查询用户
* @param id 用户id
* @return
*/
@GetMapping("/getById")
public User getUser(Long id){
return userService.getUser(id);
}
}
redis的优点
下载压测工具
登录官网Jmeter下载
https://jmeter.apache.org/
启动Jmeter工具
D:\apache-jmeter-5.4.3\bin\jmeter.bat文件双击运行。
修改语言
创建压测任务
添加HTTP请求
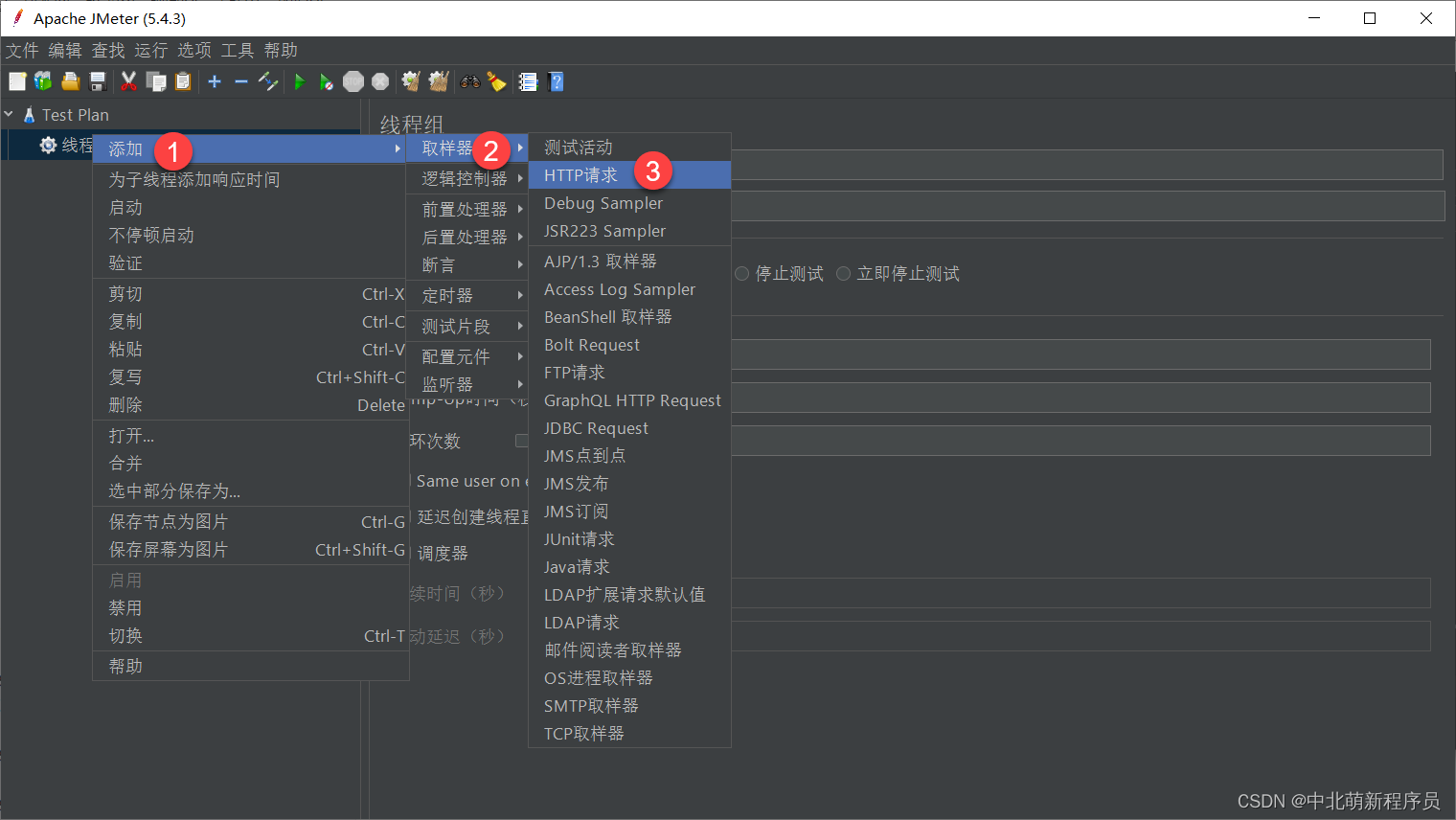
配置HTT请求
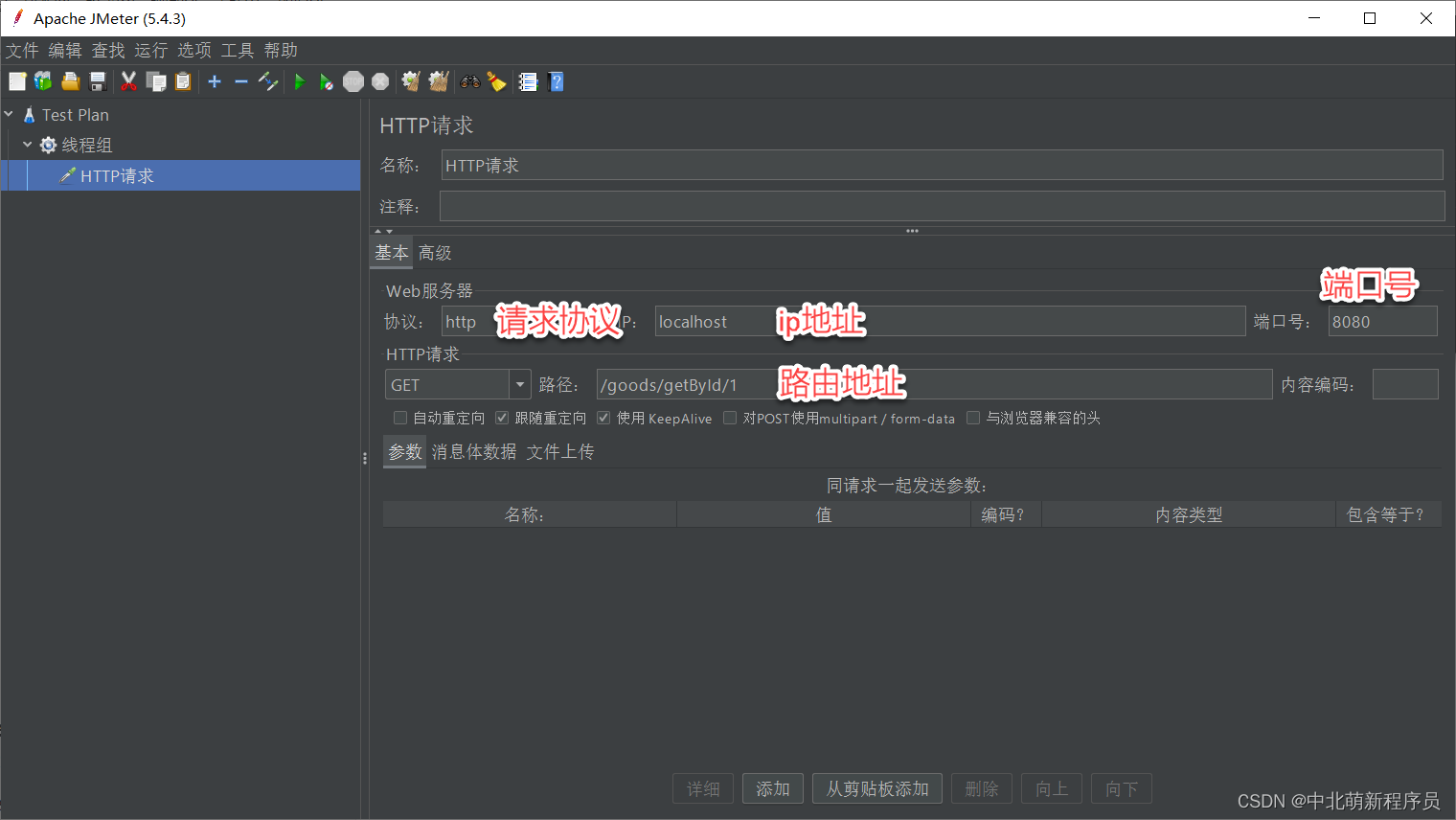
添加压测结果报告
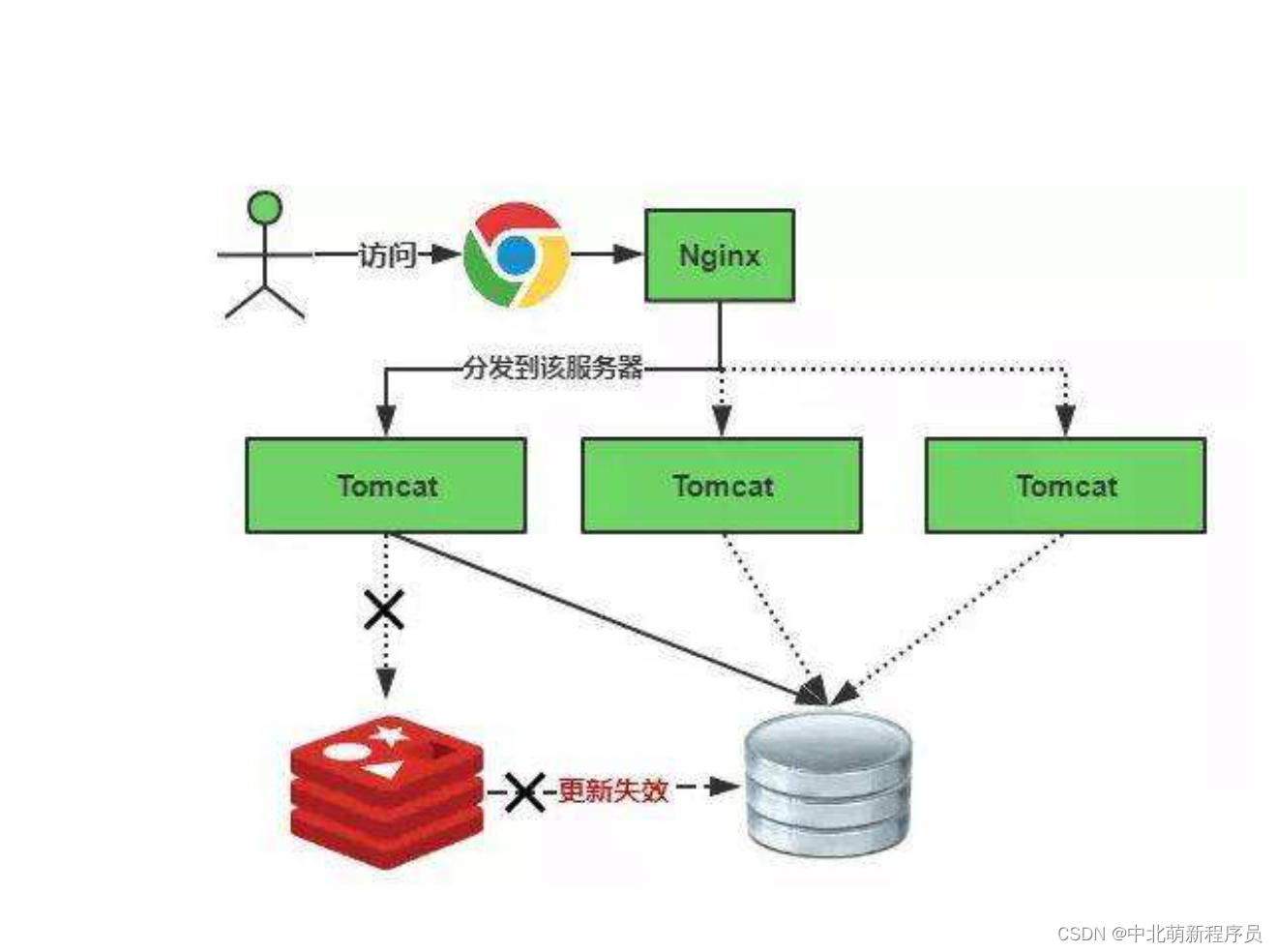
没有加缓存的吞吐量
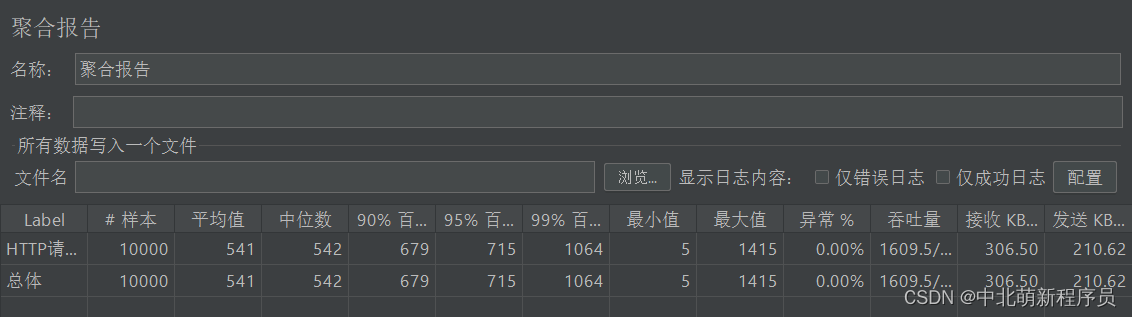
添加redis缓存
/**
*
* 根据用户id查询用户
* @param id
* @return
*/
@Override
public User getById(Long id) {
// 1、判断用户id等于1 有没有缓存 user:1
User user = (User) template.opsForValue().get("user:" + id);
if (user != null){
return user;
}
// 2、如果没有缓存从数据库查
User u = userMapper.selectById(id);
// 3、加入缓存
template.opsForValue().set("user:" + id,u);
return u;
}
继续压力测试

引入本地缓存
为什么引入本地缓存
本地缓存因为少了网络传输环节,所以读取速度比分布式缓存要快一些。
本地缓存的优点
- 减少了网络调用的开销
- 减少了数据请求的序列化和反序列化
Redis结合本地缓存
微服务场景下,多个微服务使用一个大缓存,流数据业务下,高频读取缓存对Redis压力很大,我们使用本地缓存结合Redis缓存使用,降低Redis压力,同时本地缓存没有连接开销,性能更优。
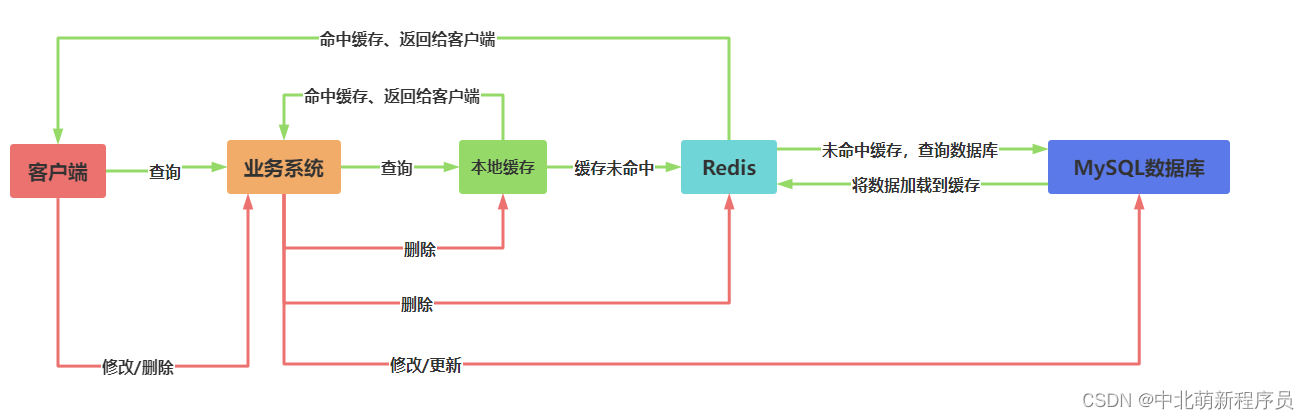
本地方案选择
本地缓存为什么不使用hashMap或者concurrentHashMap?
原因:
HashMap、ConcurrentHashMap也能用作本地缓存,但是因为缺少必要的过期机制、容量限制、数据淘汰策略,不太合适。
Google 开源工具Guava
Maven引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.2-jre</version>
</dependency>
字符串(Strings)
Strings是Guava提供的一组字符串工具,它提供了许多有用的方法来处理字符串。
Strings的主要方法:
isNullOrEmpty(String string):判断字符串是否为空或null。
padEnd(String string, int minLength, char padChar):在字符串末尾填充指定字符,直到字符串达到指定长度。
padStart(String string, int minLength, char padChar):在字符串开头填充指定字符,直到字符串达到指定长度。
repeat(String string, int count):重复指定字符串指定次数。
Strings的使用示例:
public class StringsDemo {
public static void main(String[] args) {
// 判断字符串是否为空或null
String str1 = null;
String str2 = "";
System.out.println(Strings.isNullOrEmpty(str1));
System.out.println(Strings.isNullOrEmpty(str2));
// 在字符串末尾填充指定字符,直到字符串达到指定长度
String str3 = "abc";
String paddedStr1 = Strings.padEnd(str3, 6, '*');
System.out.println(paddedStr1);
// 在字符串开头填充指定字符,直到字符串达到指定长度
String str4 = "abc";
String paddedStr2 = Strings.padStart(str4, 6, '*');
System.out.println(paddedStr2);
// 重复指定字符串指定次数
String str5 = "abc";
String repeatedStr = Strings.repeat(str5, 3);
System.out.println(repeatedStr);
}
集合操作(Collections)
Guava提供了一些非常有用的集合操作API。
ImmutableList
不可变集合是Guava的一个重要特性,它可以确保集合不被修改,从而避免并发访问的问题。ImmutabelList是不可变List的实现,下面是一个示例代码:
List<String> list = Lists.newArrayList("a", "b", "c");
ImmutableList<String> immutableList = ImmutableList.copyOf(list);
Iterables
Iterables类提供了一些有用的方法来操作集合,如下所示:
Iterable<String> iterable = Lists.newArrayList("a", "b", "c");
// 判断集合是否为空
boolean isEmpty = Iterables.isEmpty(iterable);
// 获取第一个元素,如果集合为空返回null
String first = Iterables.getFirst(iterable, null);
// 获取最后一个元素,如果集合为空返回null
String last = Iterables.getLast(iterable, null);
// 获取所有符合条件的元素
Iterable<String> filtered = Iterables.filter(iterable, new Predicate<String>() {
@Override
public boolean apply(String input) {
return input.startsWith("a");
}
});
Multimaps
Multimaps提供了一个非常有用的数据结构,它允许一个键对应多个值,下面是一个示例代码:
ListMultimap<Integer, String> map = ArrayListMultimap.create();
map.put(1, "a");
map.put(1, "b");
map.put(2, "c");
List<String> values = map.get(1); // 返回[a, b]
4.Maps
Maps提供了一些有用的方法来操作Map,如下所示:
Map<Integer, String> map = ImmutableMap.of(1, "a", 2, "b", 3, "c");
// 判断Map是否为空
boolean isEmpty = Maps.isEmpty(map);
// 获取Map中的所有键
Set<Integer> keys = map.keySet();
// 获取Map中的所有值
Collection<String> values = map.values();
// 获取Map中的所有键值对
Set<Map.Entry<Integer, String>> entries = map.entrySet();
// 根据键获取值,如果不存在则返回null
String value = Maps.getIfPresent(map, 1);
条件检查(Preconditions)
Preconditions是Guava提供的一组前置条件检查工具,它提供了一些检查参数是否符合预期的方法。
Preconditions的主要方法:
checkArgument(boolean expression, String errorMessageTemplate, Object... errorMessageArgs):检查参数是否符合预期,并抛出IllegalArgumentException异常,可以包含错误信息模板和占位符。
checkNotNull(T reference, String errorMessageTemplate, Object... errorMessageArgs):检查参数是否为null,并抛出NullPointerException异常,可以包含错误信息模板和占位符。
Preconditions的使用示例:
public class PreconditionsDemo {
public static void main(String[] args) {
// 检查参数是否符合预期,并抛出IllegalArgumentException异常,可以包含错误信息模板和占位符
String str1 = "abc";
Preconditions.checkArgument(str1.length() < 3, "字符串长度必须小于3");
// 检查参数是否为null,并抛出NullPointerException异常,可以包含错误信息模板和占位符
String str2 = null;
Preconditions.checkNotNull(str2, "字符串不能为空");
}
Guava实现本地缓存
本地缓存(CacheBuilder)
Cache是Guava提供的一个缓存工具类,它可以帮助我们在内存中缓存数据,提高程序的性能。
Cache的主要方法:
- get(K key, Callable<? extends V> valueLoader):获取指定key的缓存值,如果缓存中没有,则调用valueLoader加载数据并存入缓存。
- getIfPresent(Object key):获取指定key的缓存值,如果缓存中没有,则返回null。
- getAllPresent(Iterable<?> keys):获取指定keys的缓存值,如果缓存中没有,则返回null。
- put(K key, V value):将指定key的缓存值存入缓存。
- putAll(Map<? extends K, ? extends V> m):将指定Map的缓存值存入缓存。
- invalidate(Object key):将指定key的缓存值从缓存中删除。
- invalidateAll(Iterable<?> keys):将指定keys的缓存值从缓存中删除。
- invalidateAll():将所有缓存值从缓存中删除。
- size():获取缓存中缓存值的数量。
- asMap():将缓存转换成Map。
package com.jjy.springdataredisdemo.service.impl;
import com.google.common.cache.*;
import com.jjy.springdataredisdemo.entity.User;
import com.jjy.springdataredisdemo.mapper.UserMapper;
import com.jjy.springdataredisdemo.service.IUserService;
import lombok.SneakyThrows;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class UserServiceImpl implements IUserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RedisTemplate<String,Object> template;
/**
* 本地缓存
*/
private LoadingCache<String, User> localCache = CacheBuilder.newBuilder()
//设置并发级别为16,并发级别是指可以同时写缓存的线程数
.concurrencyLevel(16)
//设置缓存容器的初始容量为1000
.initialCapacity(1000)
//设置缓存最大容量为10000,超过10000之后就会按照LRU最近虽少使用算法来移除缓存项
.maximumSize(10000)
//设缓存1小时没被使用就过期
.expireAfterAccess(1, TimeUnit.HOURS)
//设置要统计缓存的命中率
.recordStats()
//设置缓存的移除通知
.removalListener(new RemovalListener<Object, Object>() {
@Override
public void onRemoval(RemovalNotification<Object, Object> notification) {
System.out.println(notification.getKey() + " 被移除了,原因: " + notification.getCause());
}
})
.build(new CacheLoader<String, User>() {
@Override
public User load(String key) throws Exception {
// 1、判断用户id等于1 有没有缓存 user:1
User user = (User) template.opsForValue().get("user:" + key);
if (user != null){
return user;
}
// 2、查询数据库
User users = userMapper.selectById(key);
// 4、加入redis分布式缓存
template.opsForValue().set("user:" + key,users);
return users;
}
});
/**
*
* 根据用户id查询用户
* @param id
* @return
*/
@SneakyThrows
@Override
public User getById(Long id) {
// 1、从本地缓存获取
User o = localCache.get(id+"");
return o;
}
能够高效的读取的同时,提供了大量api方便我们控制本地缓存的数据量及冷数据淘汰;我们充分的学习这些特性能够帮助我们在业务开发中更加轻松灵活,在空间与时间上找到一个平衡点。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力